
Схема загрузки
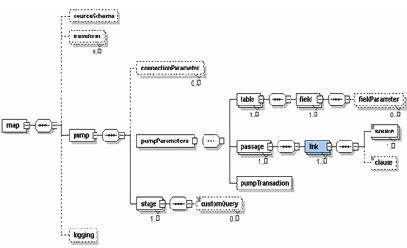
Рис. 2 Схема карты загрузки
Одним из самых мощных интерфейсов доступа к содержимому XML документов является Document Object Model - DOM.
Объектная модель XML документов является представлением его внутренней структуры в виде совокупности определенных объектов. Для удобства эти объекты организуются в некоторую древообразную структуру данных - каждый элемент документа может быть отнесен к отдельной ветви, а все его содержимое, в виде набора вложенных элементов, комментариев, секций CDATA и т.д. представляется в этой структуре поддеревьями. Так как в любом правильно составленном XML-документе обязательно определен главный элемент, то все содержимое можно рассматривать как поддеревья этого основного элемента, называемого в таком случае корнем дерева документа.
DOM - это спецификация универсального платформо- и программно-независимого доступа к содержимому документов и является просто своеобразным API для их обработчиков. DOM является стандартным способом построения объектной модели любого HTML или XML документа, при помощи которой можно производить поиск нужных фрагментов, создавать, удалять и модифицировать его элементы.
Для описания интерфейсов доступа к содержимому XML документов в спецификации DOM применяется платформо-независимый язык IDL и для использования их необходимо "перевести" на какой-то конкретный язык программирования. Однако этим занимаются создатели самих анализаторов, и разработчику можно ничего не знать о способе реализации интерфейсов - с точки зрения разработчиков прикладных программ DOM выглядит как набор объектов с определенными методами и свойствами.
Достоинством модели DOM является тот факт, что загрузчик получает произвольный доступ к элементам документа. Однако обработка документов большого объема потребует значительных вычислительных ресурсов.
Другим подходом при обработке XML-документов является модель SAX. Он построен на механизме обратных вызовов. Пользователь должен предоставить класс, который будет реагировать на события разбора XML (или игнорировать их). Примерами таких событий являются начало документа, начало тэга и т. п.
Использование модель SAX для обработки XML-документов в данном случает представляется более разумным при реализации загрузчика, поскольку не требует значительных ресурсов памяти. Однако, при использовании модели SAX обработка документа будет происходить последовательно. Элементы документа будут обрабатываться в том порядке, в каком они встречаются в документе.
Данное обстоятельство не позволяет обрабатывать элементы документа в произвольном порядке, что может понадобиться при загрузке, в случае, если например таблицы должны быть связаны по уникальным идентификаторам со справочниками, а данные справочника расположены в документе после основных данных.
Для разрешения таких ситуаций в спецификации на карту загрузки существует элемент <passage></passage> , который позволяет задавать несколько проходов обработки входного документа со своими настройками связок обработки данных. Таким образом, можно определить первый проход, который будет обрабатывать данные справочников, а вторым проходом определить обработку данных таблицы с установлением идентификаторов из справочников.